Hugging Face 入门 (Transformers/Tokenizer/Pipeline)
Hugging Face 入门 (Transformers/Tokenizer/Pipeline)
Hugging Face 是一个开源的自然语言处理(NLP)库,提供了许多工具和模型,帮助用户进行文本处理、模型调用和预训练模型的微调等任务。
下面介绍了一些与 Hugging Face 相关的重要概念和步骤。
Transformers
Transformers 是 Huggingface 开源的基于 transformer 模型结构提供的预训练语言库,支持 PyTorch 和 TensorFlow2.0。
它提供了快速的模型调用功能,并支持模型的进一步训练和微调。
Tokenizer
Tokenizer 是 Transformers 库中的一个重要模块,用于将文本数据切分成单独的标记(tokens)并进行编码,以便交给模型进行处理。
在自然语言处理(NLP)中,将文本转换成标记是一个重要的预处理步骤。
不同的模型可能使用不同类型的 Tokenizer 来处理文本数据,例如 BERTTokenizer、GPT2Tokenizer 等。
Pipeline
HuggingFace 提供了一个接口,称为 Pipeline,使得在 Transformers 库中使用预训练模型更加简单。
通过 Pipeline,您可以轻松地对输入文本进行处理并获取模型的输出结果,而无需手动进行繁琐的预处理和后处理步骤。
例如,您可以使用 TextClassificationPipeline 对输入文本进行分类,或使用 TextGenerationPipeline 生成一段文本。
基于 bart-large-cnn 模型进行文本摘要生成
以下是进行文本摘要生成的步骤:
安装 Transformers 包。
1
!pip install transformers datasets --quiet
定义所需的模型 ID,facebook/bart-large-cnn
1
model_id = "facebook/bart-large-cnn"
准备要进行摘要生成的文本,将其赋值给变量 content。
1
2
3
4
5
6
7content = """
The explosion of consumer-facing tools that offer generative AI has created plenty of debate: These tools promise to transform the ways in which we live and work while also raising fundamental questions about how we can adapt to a world in which they're extensively used for just about anything.
As with any new technology riding a wave of initial popularity and interest, it pays to be careful in the way you use these AI generators and bots—in particular, in how much privacy and security you're giving up in return for being able to use them.
It's worth putting some guardrails in place right at the start of your journey with these tools, or indeed deciding not to deal with them at all, based on how your data is collected and processed. Here's what you need to look out for and the ways in which you can get some control back.
"""使用 Transformers 库中的 pipeline 函数调用模型,其中 pipline 第一个参数 task 表示模型执行任务。
1
2
3from transformers import pipeline
pipeline = pipeline("summarization", model=model_id)
https://huggingface.co/docs/transformers/quicktour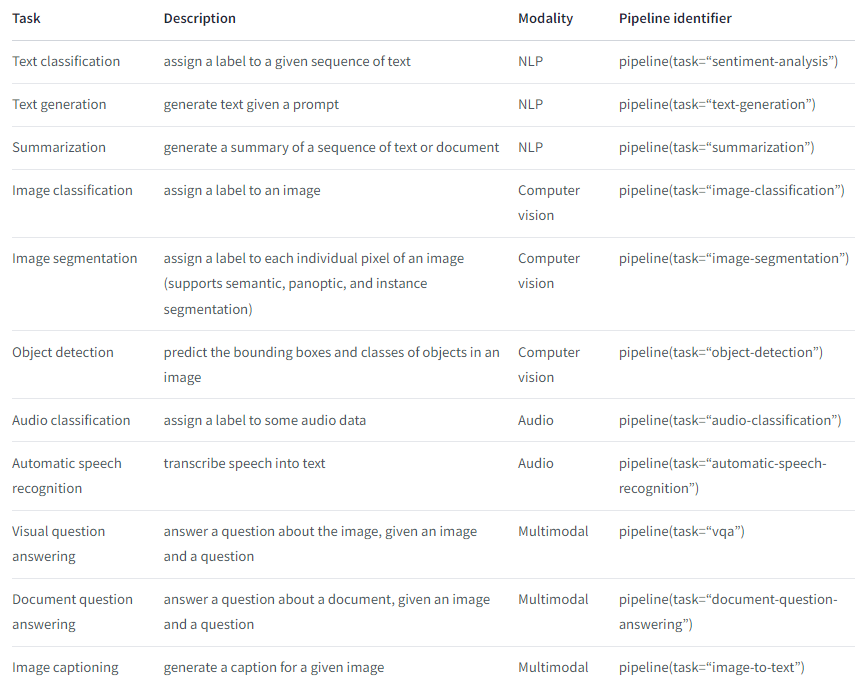
- 输出生成的摘要内容。以上是使用 BART-large-cnn 模型进行文本摘要生成的简要示例。
1
2
3pipeline(content)
[{'summary_text': "The explosion of consumer-facing tools that offer generative AI has created plenty of debate. It's worth putting some guardrails in place right at the start of your journey with these tools. Here's what you need to look out for and the ways in which you can get some control back."}]
总结:
通过 Hugging Face 的 Transformers 库,我们可以轻松地使用预训练的 transformer 模型进行文本处理和任务执行。
Tokenizer 模块帮助我们将文本数据切分成标记。
而 Pipeline 接口则简化了模型调用和结果获取的过程。
通过以上示例,您可以快速开始使用 Hugging Face 进行文本摘要生成的任务。

