Hugging Face入门 (模型文件详解)
Hugging Face入门 (模型文件详解)
Hugging face Llama-2 模型文件详解
当使用 AutoClass 或者 pipeline() 进行模型加载时,我们会看到从Hugging face上下载模型相关文件。
这些文件有什么作用?今天我们就以模型 meta-llama/Llama-2-7b-chat-hf 为例,介绍模型的文件组成。
模型文件详解
Llama-2 Huggingface 文件构成如下图所示:
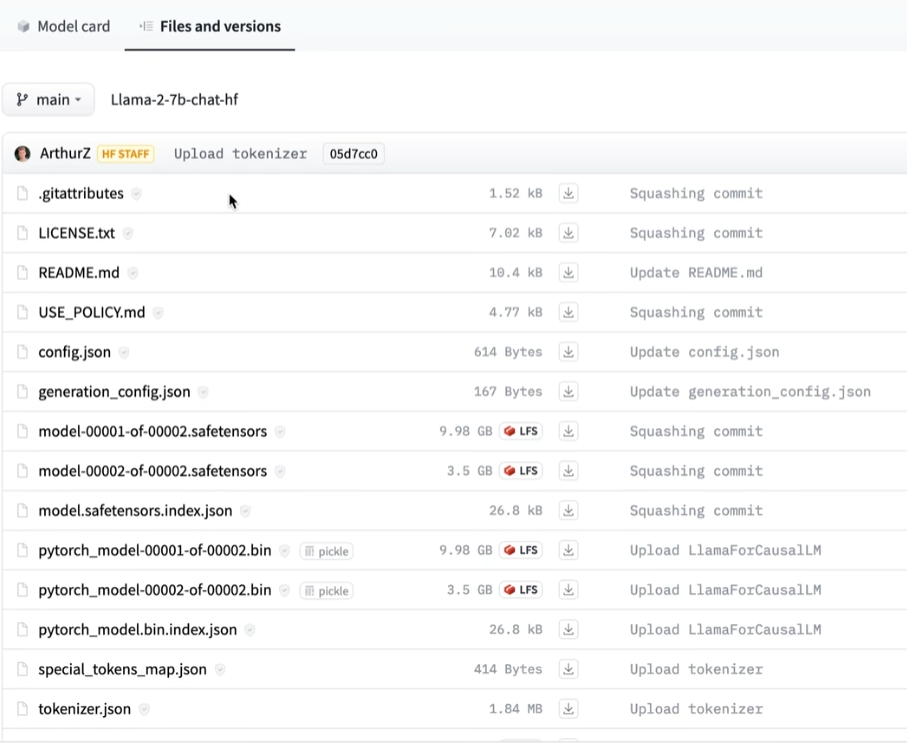
Huggingface 文件介绍
| 文件名 | 描述 |
|---|---|
| config.json | 模型的主要配置信息,如 Bert 模型设置、预测头部设置、训练参数等 |
| generation_config.json | 文本生成相关的模型配置 |
| model-00001-of-00002.safetensors | safetensors 文件格式的模型权重参数的分块 |
| model-00002-of-00002.safetensors | safetensors 文件格式的模型权重参数的分块 |
| model.safetensors.index.json | safetensors 模型参数文件的索引,描述了模型切片的信息 |
| pytorch_model-00001-of-00002.bin | pickle 序列化的 PyTorch 模型权重参数的分块 |
| pytorch_model-00002-of-00002.bin | pickle 序列化的 PyTorch 模型权重参数的分块 |
| pytorch_model.bin.index.json | pickle 序列化的 PyTorch 模型索引,描述了模型切片的信息 |
| special_tokens_map.json | tokenizer 中特殊标记符(special tokens)到数字 ID 的映射关系 |
| tokenizer.json | tokenizer 的配置信息,如字典大小、tokenize 策略等 |
| tokenizer.model | tokenizer 的具体模型参数,经过训练得到的二进制文件 |
| tokenizer_config.json | 使用该 tokenizer 时的配置,如最大序列长度等 |
模型切片的索引信息
一个完整的大型模型通常会被切分成多个碎片(shards),并以 model-00001-of-00002.safetensors 这种命名方式保存。pytorch_model.bin.index.json 文件包含所有的模型切片信息,主要包括:
模型切片的总数。
每个切片的元数据,如名称、偏移地址、文件大小等。
切片如何组合起来重新组成完整模型的说明。
一些额外的模型信息,如模型名称、框架版本等元数据。
Tokenizer 特殊标记符(Special Tokens)
special_tokens_map.json 包含 Tokenizer 特殊标记符(Special Tokens)到其对应的数字 ID 的映射。
一些常见的特殊标记符定义包括:
unk_token:未登录词(out-of-vocabulary words)的标记 ID。sep_token:句子分隔的标记 ID。pad_token:填充序列到相等长度时使用的填充标记 ID。cls_token:分类任务中使用的分类标记 ID。mask_token:掩码语言模型任务中使用的掩码标记 ID。
safetensors 文件
safetensors 是一种安全快速存储和加载 tensors 的文件格式。
通常,PyTorch 模型权重会使用 Python 的 pickle 工具将数据序列化到一个 .bin 文件中。
然而,pickle 不安全,pickle 的文件可能包含可以执行的恶意代码。safetensors 是 pickle 的一个安全替代方案,非常适合共享模型权重。
有关使用 Safetensors 的详细信息,请参考 Using Safetensors。

